

Uji normalitas Kolmogorov-Smirnov, atau kadang dirujuk lebih singkat sebagai uji Kolmogorov-Smirnov (uji K-S) adalah uji statistis yang digunakan untuk memeriksa kenormalan dari data sampel yang diberikan. Dengan kata lain, uji K-S digunakan untuk memeriksa apakah suatu data berasal dari distribusi normal atau bukan. Sesuai namanya, uji ini dirancang oleh dua orang matematikawan Soviet, yaitu Andrey Nikolaevich Kolmogorov (1903–1987) dan Nikolai Vasilyevich Smirnov (1900–1966). Uji K-S merupakan salah satu uji nonparametrik sehingga penggunaannya tidak melibatkan adanya asumsi terkait distribusi yang mendasari data yang akan diuji.
Uji K-S melibatkan perbandingan fungsi distribusi kumulatif dari data sampel dengan fungsi distribusi kumulatif dari suatu distribusi normal yang memiliki rata-rata dan simpangan baku yang sama seperti data sampel. Jika sampel berdistribusi normal, fungsi distribusi kumulatifnya seharusnya mendekati/serupa dengan fungsi distribusi kumulatif dari distribusi normal tersebut.
Statistik uji yang digunakan dalam uji K-S adalah jarak maksimum $(d)$ dari dua nilai fungsi distribusi kumulatif yang terlibat. Jarak tersebut dihitung sebagai selisih positif terbesar dari nilai fungsi distribusi kumulatif sampel dan distribusi normal di sepanjang titik-titik yang terdefinisi dalam distribusi.
Perlu dicatat bahwa uji K-S hanya dapat diaplikasikan pada data kontinu dan cukup sensitif terhadap ukuran sampel. Oleh karena itu, penggunaan uji tersebut sebaiknya diikuti oleh uji normalitas yang lain atau melibatkan analisis secara visual dari data yang diolah. Lebih lanjut, uji tersebut juga hanya berlaku pada data tunggal (ungrouped data), bukan data kelompok.
Baca: Materi, Soal, dan Pembahasan – Uji Rata-Rata Satu Populasi
Rumusan hipotesis yang diajukan ketika melakukan uji K-S adalah sebagai berikut.
$$\begin{array}{lll} \text{Hipotesis nol} & : & \text{Data berdistribusi normal}. \\ \text{Hipotesis alternatif} & : & \text{Data tidak berdistribusi normal}. \\ \end{array}$$Statistik uji yang akan dihitung dalam uji K-S cukup rumit jika dikerjakan secara manual. Oleh karena itu, kita akan mengerjakannya secara semi-manual dengan menggunakan bantuan aplikasi Microsoft Excel.
Sebagai contoh, diberikan data tunggal nilai sejumlah siswa sebagai berikut.
$$\begin{array}{c|cccccccccccc}\textbf{Nilai} & 70 & 50 & 30 & 10 & 100 & 40 & 30 & 50 \end{array}$$Untuk menguji normalitas data tersebut, langkah pertama yang perlu dilakukan adalah memasukkan data tersebut ke dalam Excel untuk diolah. Kemudian, lengkapi informasi terkait ukuran data, rata-rata, dan simpangan baku seperti gambar di bawah. Rumus Excel yang digunakan untuk menghitung ukuran data adalah =COUNT(A2:A9). Rata-rata dan simpangan baku berturut-turut dihitung dengan menggunakan rumus $=\text{AVERAGE}(A2:A9)$ dan $=\text{STDEV.S}(A2:A9).$
Rumus Excel yang digunakan untuk menghitung ukuran data adalah =COUNT(A2:A9). Rata-rata dan simpangan baku berturut-turut dihitung dengan menggunakan rumus $=\text{AVERAGE}(A2:A9)$ dan $=\text{STDEV.S}(A2:A9).$
Selanjutnya, buat tabel baru yang meliputi $7$ kolom, yaitu kolom $X,$ Frekuensi, $f(X),$ $F(X),$ $Z,$ $F(Z),$ dan $d = |F(X)-F(Z)|.$ Kolom frekuensi menginformasikan banyaknya kemunculan datum dengan nilai tertentu. $f(X)$ menyatakan fungsi distribusi, yaitu hasil bagi dari frekuensi datum oleh frekuensi keseluruhan (ukuran sampel). Sebagai contoh, untuk $X = 30,$ frekuensinya bernilai $2,$ sedangkan frekuensi keseluruhan (ukuran sampel) sama dengan $8$ sehingga $f(30) = 2/8 = 0,\!25.$ Lebih lanjut, $F(X)$ menyatakan fungsi distribusi kumulatif dari $f(X).$ Kemudian, $Z$ merupakan nilai-$z,$ yaitu nilai normal baku yang merupakan hasil transformasi dari $X$ dengan melibatkan rata-rata sampel $\overline{x}$ dan simpangan baku sampel $s,$ yaitu
$$Z = \dfrac{X-\overline{x}}{s}.$$Di kolom sampingnya, $F(Z)$ menyatakan nilai peluang yang direpresentasikan oleh luas daerah di sebelah kiri titik $z.$ Umumnya, kita menggunakan tabel-$z$ untuk menentukan $F(Z).$ Namun, karena nilai-$z$ sendiri berupa bilangan irasional, kita dianjurkan memanfaatkan Excel untuk menentukan $F(Z)$ agar perhitungan menjadi lebih presisi. Kita dapat menggunakan fungsi $\text{NORM.DIST}.$ Sebagai contoh, rumus yang digunakan untuk menentukan $F(Z)$ pada saat $X = 10$ adalah $$=\text{NORM.DIST(F2; \$D\$3; \$D\$4; TRUE)}.$$Pada kolom terakhir, nilai $d$ dihitung dengan mencari selisih positif dari $F(X)$ dan $F(Z).$ Tanda mutlak di Excel dimasukkan dengan menggunakan fungsi $\text{ABS}.$

Terakhir, $d$ maksimum dihitung dengan menentukan nilai $d$ yang paling besar. Dengan menggunakan Excel, gunakan fungsi $\text{MAX}.$ Dalam hal ini, $d$ maksimum yang diperoleh adalah $$\boxed{d_{\text{maks}} \approx 0,\!21397}.$$Inilah nilai statistik uji yang kita inginkan saat menjalankan uji K-S. Anda dapat mengakses data pada perhitungan yang telah dilakukan di atas melalui tautan ini pada sheet Contoh.
Setelah nilai statistik uji didapat, langkah berikutnya adalah menentukan nilai kritis Kolmogorov-Smirnov yang dapat diketahui melalui tabel K-S. Pada tabel tersebut, kolom menyatakan taraf signifikansi yang digunakan, sedangkan baris menyatakan ukuran sampel. Sebagai contoh, jika taraf signifikansi yang digunakan adalah $\alpha = 5\%,$ sedangkan ukuran sampel dari data yang diberikan di atas adalah $8,$ maka nilai kritis K-S dalam kasus ini adalah $d_{0,05; ~8} \approx 0,\!45427.$ Daerah kritis terletak di $d > 0,\!45427.$
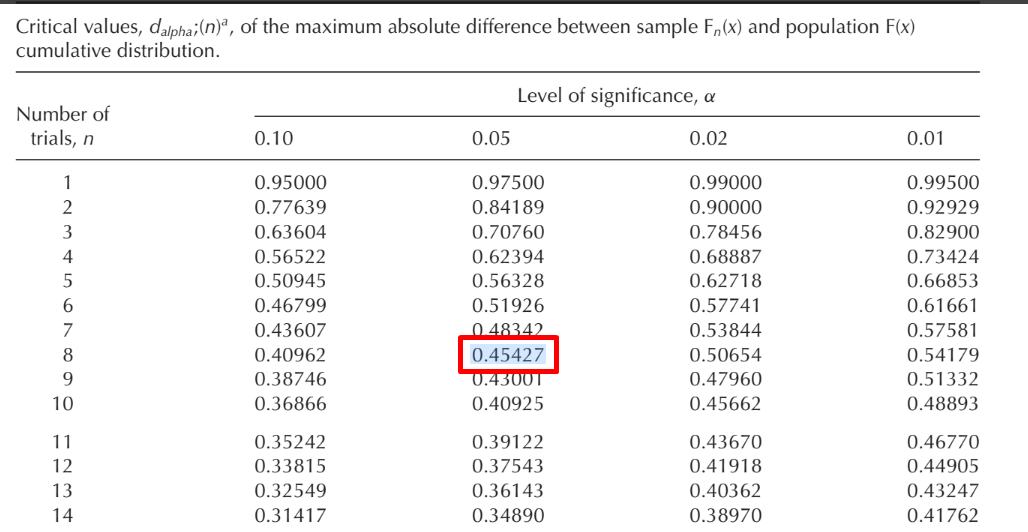
Langkah terakhir adalah membandingkan nilai statistik uji $d_{\text{maks}}$ dan nilai kritis K-S $d_{0,05; ~8}.$ Jika $d_{\text{maks}}$ lebih kecil dari nilai kritis K-S, maka $H_0$ tidak ditolak sehingga data disimpulkan berdistribusi normal. Sebaliknya, jika $d_{\text{maks}}$ lebih besar atau sama dengan nilai kritis K-S, maka $H_0$ ditolak sehingga data disimpulkan tidak berdistribusi normal.
Artikel ini ditulis berdasarkan beberapa sumber, termasuk sumber berbahasa Inggris. Oleh karena itu, untuk meminimalisasi kesalahan penafsiran, padanan untuk beberapa kata/istilah diberikan dalam tabel berikut.
$$\begin{array}{ccc} \hline \text{No.} & \text{Bahasa Indonesia} & \text{Bahasa Inggris} \\ \hline 1. & \text{Uji Kolmogorov-Smirnov} & \text{Kolmogorov-Smirnov Test} \\ 2. & \text{Distribusi Normal} & \text{Normal Distribution} \\ 3. & \text{Fungsi Distribusi Kumulatif} & \text{Cumulative Distribution Function} \\ 4. & \text{Uji Nonparametrik} & \text{Nonparametric Test} \\ 5. & \text{Statistik Uji} & \text{Test Statistics} \\ 6. & \text{Nilai Kritis} & \text{Critical Value} \\ 7. & \text{Daerah Kritis} & \text{Critical Region} \\ 8. & \text{Taraf Signifikansi} & \text{Significance Value} \\ \hline \end{array}$$
Quote by Karl Pearson
Catatan: Hasil perhitungan yang dilakukan dalam setiap soal bisa jadi sedikit berbeda karena masalah pembulatan. Anda seharusnya tidak dianggap salah jika terjadi kasus seperti itu.
Bagian Uraian
Soal Nomor 1
Seorang peneliti ingin melakukan studi terkait kemampuan berpikir kreatif pada siswa kelas X di suatu sekolah. Sebelum itu, ia perlu menguji normalitas data nilai siswa kelas X di sekolah tersebut. Oleh karena itu, ia mengambil data sampel berupa $10$ nilai siswa yang diperoleh saat penilaian sumatif semester sebelumnya, yaitu sebagai berikut.
$$\begin{array}{c|cccccccccccc}\textbf{Nilai} & 50 & 60 & 90 & 40 & 100 & 80 & 50 & 50 & 60 & 90 \end{array}$$Dengan menggunakan uji Kolmogorov-Smirnov, ujilah normalitas data nilai siswa kelas X tersebut pada taraf signifikansi $5\%.$
Misalkan $X$ merupakan variabel acak kontinu yang menyatakan nilai siswa kelas X di sekolah tersebut.
Rumusan hipotesis:
$$\begin{array}{lll} \text{Hipotesis nol} & : & \text{Data berdistribusi normal}. \\ \text{Hipotesis alternatif} & : & \text{Data tidak berdistribusi normal}. \\ \end{array}$$Statistik uji:
Dari data sampel yang diberikan, dengan menggunakan bantuan Excel (lihat sheet Nilai), diperoleh informasi penting berikut.
$$\begin{aligned} n & = 10 \\ \overline{x} & = 67 \\ s & \approx 21,\!1081 \end{aligned}$$Perhitungan akhir menunjukkan bahwa nilai $d_{\text{maks}} \approx 0,\!22991.$
Daerah kritis:
Berdasarkan tabel K-S, nilai kritis K-S pada tingkat signifikansi $\alpha = 5\% = 0,\!05$ dan ukuran sampel $n = 10$ adalah $d_{0,05;~10} \approx 0,\!40925.$ Dengan demikian, daerah kritis terletak di $d > 0,\!40925.$
Keputusan:
Karena $d_{\text{maks}} = 0,\!22991 < 0,\!40925 =d_{0,05;~10},$ disimpulkan bahwa statistik uji tidak jatuh pada daerah kritis. Dengan demikian, $H_0$ tidak ditolak.
Kesimpulan:
Pada taraf signifikansi $5\%,$ data nilai siswa kelas X tersebut berdistribusi normal.
Baca: Materi, Soal, dan Pembahasan – Uji Selisih Rata-Rata Dua Populasi Berpasangan
Soal Nomor 2
Sebanyak $8$ pasien di rumah sakit X dipilih secara acak untuk diukur berat badannya (dalam kg). Data berat badan pasien tersebut disajikan dalam tabel berikut.
$$\begin{array}{c|cccccccccccc} \textbf{Berat Badan} & 50 & 56 & 60 & 70 & 65 & 60 & 57 & 52 \end{array}$$Dengan menggunakan uji Kolmogorov-Smirnov, ujilah normalitas data berat badan pasien di rumah sakit tersebut pada taraf signifikansi $5\%.$
Misalkan $X$ merupakan variabel acak kontinu yang menyatakan berat badan pasien (dalam kg) di rumah sakit tersebut.
Rumusan hipotesis:
$$\begin{array}{lll} \text{Hipotesis nol} & : & \text{Data berdistribusi normal}. \\ \text{Hipotesis alternatif} & : & \text{Data tidak berdistribusi normal}. \\ \end{array}$$Statistik uji:
Dari data sampel yang diberikan, dengan menggunakan bantuan Excel (lihat sheet Berat Badan), diperoleh informasi penting berikut.
$$\begin{aligned} n & = 8 \\ \overline{x} & = 58,\!75 \\ s & \approx 6,\!5628 \end{aligned}$$Perhitungan akhir menunjukkan bahwa nilai $d_{\text{maks}} \approx 0,\!17447.$
Daerah kritis:
Berdasarkan tabel K-S, nilai kritis K-S pada tingkat signifikansi $\alpha = 5\% = 0,\!05$ dan ukuran sampel $n = 8$ adalah $d_{0,05;~8} \approx 0,\!45427.$ Dengan demikian, daerah kritis terletak di $d > 0,\!45427.$
Keputusan:
Karena $d_{\text{maks}} =0,\!17447 < 0,\!45427 =d_{0,05;~8},$ disimpulkan bahwa statistik uji tidak jatuh pada daerah kritis. Dengan demikian, $H_0$ tidak ditolak.
Kesimpulan:
Pada taraf signifikansi $5\%,$ data berat badan pasien di rumah sakit tersebut berdistribusi normal.
Soal Nomor 3
Seorang biolog melakukan penelitian terhadap tinggi kecambah kacang hijau (Vigna radiata) yang diletakkan di tempat dengan kondisi cahaya yang remang-remang. Sebanyak $11$ biji kacang hijau disiapkan, kemudian tinggi kecambah kacang hijau (dalam cm) yang tumbuh pada hari ke-6 diukur sehingga diperoleh data berikut.
$$\begin{array}{c|cccccccccccc} \textbf{Tinggi Kecambah} & 3,\!4 & 3,\!8 & 4,\!0 & 3,\!9 & 2,\!5 & 2,\!8 & 3,\!0 & 5,\!0 & 4,\!6 & 4,\!5 & 4,\!2 \end{array}$$Dengan menggunakan uji Kolmogorov-Smirnov, ujilah normalitas data tinggi kecambah kacang hijau tersebut pada taraf signifikansi $10\%.$
Misalkan $X$ merupakan variabel acak kontinu yang menyatakan tinggi kecambah kacang hijau (dalam cm) tersebut.
Rumusan hipotesis:
$$\begin{array}{lll} \text{Hipotesis nol} & : & \text{Data berdistribusi normal}. \\ \text{Hipotesis alternatif} & : & \text{Data tidak berdistribusi normal}. \\ \end{array}$$Statistik uji:
Dari data sampel yang diberikan, dengan menggunakan bantuan Excel (lihat sheet Kecambah Kacang Hijau), diperoleh informasi penting berikut.
$$\begin{aligned} n & = 11 \\ \overline{x} & \approx 3,\!7909 \\ s & \approx 0,\!7918 \end{aligned}$$Perhitungan akhir menunjukkan bahwa nilai $d_{\text{maks}} \approx 0,\!11381.$
Daerah kritis:
Berdasarkan tabel K-S, nilai kritis K-S pada tingkat signifikansi $\alpha = 10\% = 0,\!1$ dan ukuran sampel $n = 11$ adalah $d_{0,1;~11} \approx 0,\!35242.$ Dengan demikian, daerah kritis terletak di $d > 0,\!35242.$
Keputusan:
Karena $d_{\text{maks}} = 0,\!11381< 0,\!35242 =d_{0,1;~11},$ disimpulkan bahwa statistik uji tidak jatuh pada daerah kritis. Dengan demikian, $H_0$ tidak ditolak.
Kesimpulan:
Pada taraf signifikansi $10\%,$ data tinggi kecambah kacang hijau (dalam cm) tersebut berdistribusi normal.
Soal Nomor 4
Sebanyak $20$ orang dewasa dipilih secara acak untuk dicatat ukuran sepatu yang digunakan. Data tersebut disajikan dalam tabel berikut.
$$\begin{array}{c|c} \textbf{Ukuran Sepatu} & \textbf{Frekuensi} \\ \hline 38 & 3 \\ 39 & 5 \\ 40 & 2 \\ 41 & 1 \\ 42 & 5 \\ 43 & 4 \\ \hline \end{array}$$Dengan menggunakan uji Kolmogorov-Smirnov, ujilah normalitas data ukuran sepatu tersebut pada taraf signifikansi $1\%.$
Misalkan $X$ merupakan variabel acak kontinu yang menyatakan ukuran sepatu.
Rumusan hipotesis:
$$\begin{array}{lll} \text{Hipotesis nol} & : & \text{Data berdistribusi normal}. \\ \text{Hipotesis alternatif} & : & \text{Data tidak berdistribusi normal}. \\ \end{array}$$Statistik uji:
Dari data sampel yang diberikan, dengan menggunakan bantuan Excel (lihat sheet Ukuran Sepatu), diperoleh informasi penting berikut.
$$\begin{aligned} n & = 20 \\ \overline{x} & = 40,\!6 \\ s & \approx 1,\!8750 \end{aligned}$$Perhitungan akhir menunjukkan bahwa nilai $d_{\text{maks}} \approx 0,\!20326.$
Daerah kritis:
Berdasarkan tabel K-S, nilai kritis K-S pada tingkat signifikansi $\alpha = 1\% = 0,\!01$ dan ukuran sampel $n = 20$ adalah $d_{0,01;~20} \approx 0,\!35241.$ Dengan demikian, daerah kritis terletak di $d > 0,\!35241.$
Keputusan:
Karena $d_{\text{maks}} = 0,\!20326< 0,\!35241 =d_{0,01;~20},$ disimpulkan bahwa statistik uji tidak jatuh pada daerah kritis. Dengan demikian, $H_0$ tidak ditolak.
Kesimpulan:
Pada taraf signifikansi $1\%,$ data ukuran sepatu tersebut berdistribusi normal.
Soal Nomor 5
Suatu acara kuis diikuti oleh $100$ peserta. Dari $10$ soal yang diberikan, banyaknya orang yang menjawab sejumlah soal dengan benar diberikan dalam tabel berikut.
$$\begin{array}{c|c} \textbf{Banyaknya Jawaban yang Benar} & \textbf{Frekuensi} \\ \hline 4 & 10 \\ 5 & 15 \\ 6 & 18 \\ 7 & 20 \\ 8 & 17 \\ 9 & 12 \\ 10 & 8 \\ \hline \end{array}$$Dengan menggunakan uji Kolmogorov-Smirnov, ujilah normalitas data banyaknya jawaban yang benar tersebut pada taraf signifikansi $2\%.$
Misalkan $X$ merupakan variabel acak diskret yang menyatakan banyaknya jawaban yang benar.
Rumusan hipotesis:
$$\begin{array}{lll} \text{Hipotesis nol} & : & \text{Data berdistribusi normal}. \\ \text{Hipotesis alternatif} & : & \text{Data tidak berdistribusi normal}. \\ \end{array}$$Statistik uji:
Dari data sampel yang diberikan, dengan menggunakan bantuan Excel (lihat sheet Kuis), diperoleh informasi penting berikut.
$$\begin{aligned} n & = 100 \\ \overline{x} & = 6,\!87 \\ s & \approx 1,\!7503 \end{aligned}$$Perhitungan akhir menunjukkan bahwa nilai $d_{\text{maks}} \approx 0,\!12042.$
Daerah kritis:
Berdasarkan tabel K-S, nilai kritis K-S pada tingkat signifikansi $\alpha = 2\% = 0,\!02$ dan ukuran sampel $n = 100$ adalah $d_{0,02;~100} \approx 0,\!151.$ Dengan demikian, daerah kritis terletak di $d > 0,\!151.$
Keputusan:
Karena $d_{\text{maks}} = 0,\!12042< 0,\!151 =d_{0,02;~100},$ disimpulkan bahwa statistik uji tidak jatuh pada daerah kritis. Dengan demikian, $H_0$ tidak ditolak.
Kesimpulan:
Pada taraf signifikansi $2\%,$ data banyaknya jawaban yang benar tersebut berdistribusi normal.